Pytorch Tensorrt 적용
TensorRT는 Deep Learning 모델을 최적화해 GPU에서 inference 속도를 향상시킬 수 있는 최적화 엔진이다. TensorRT는 GPU에서 최적화된 성능을 낼 수 있도록 Network Compression, Netword Optimization을 진행한다.
Quantization & Precision Calibration
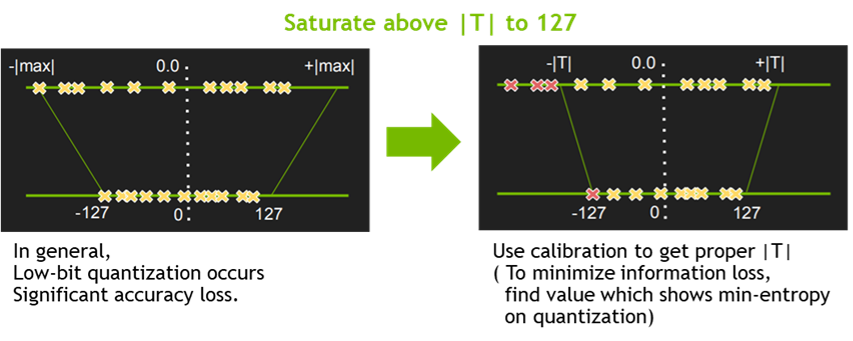
quantization을 통한 precision reduction은 network의 파라미터의 bit가 작기 떄문에 더 좋은 성능을 발휘할 수 있다. TensorRT는 Symmetric Linear Quantization을 사용하고 있으며, float32 데이터를 float16, int8로 낮출 수 있다. 하지만 int8로 precision을 낮추면 숫자표현이 급격히 줄어들어 성능에서 문제가 생긴다. 따라서 TensorRT는 callibration을 통해 weight과 intermidiate tensor에서의 정보손실을 최소화한다.
Graph Optimization
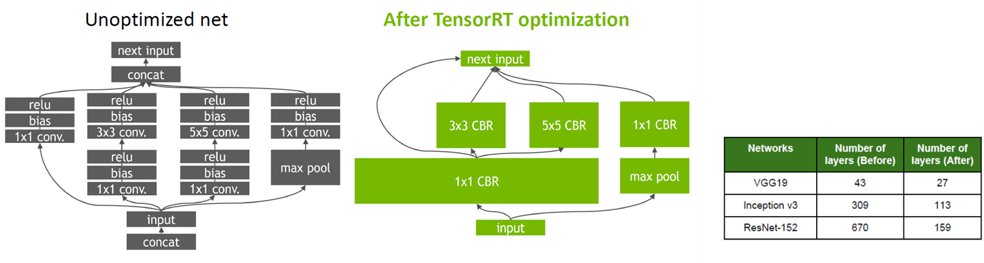
TensorRT는 또한 platform에 최적화된 graph를 위해 Layer Fusion 방식과 Tensor Fusion을 사용한다. 따라서 Vertical Layer Fusion, Horizontal Layer Fusion, Tensor Fusion이 적용되어 graph를 단순하게 만들어 속도를 높힌다.
Etc
Kernel Auto-tuning을 통해 GPU의 cuda core 수, 아키텍쳐 등을 고려하여 optimization을 진행하고, Dynamic Tensor Memory & Multi-stream execution을 통해 footprint를 줄여 성능을 높힌다.
TensorRT설치
필자 Docker를 사용하므로 Docker를 기준으로 설명하겠다.
1. 도커 설치
Ubuntu, Window(WSL2), 이렇게가 설치방법인데 Window는 미리 WSL2를 이용해 Nvidia-Driver를 설치해야한다. (해봤는데 정말 귀찮다) 그리고 MacOS는 Nvidia GPU를 사용할 수 없으니 사실상 사용을 못한다.
2. Docker container만들기
먼저 nvidia-smi를 사용하여 cuda version을 확인한다.
nvidia-smi

위의 사진을 보고 자신의 cuda toolkit version에 맞는 컨테이너 버전을 사용하자. 추가적인 cuda version은 TensorRT Container Release Notes 이 링크를 이용하면 된다. 그 다음 container버전과 python버전을 채워넣어 docker image를 pull하면 된다.
docker pull nvcr.io/nvidia/tensorrt:<xx.xx>-py<x>
예 container version 22.06, python3 사용
docker pull nvcr.io/nvidia/tensorrt:22.06-py3
그 후 container를 만들어 run하면 된다. Docker 19.03 또는 그 이후 버전을 사용하면
docker run --gpus all -it --name tensorrt nvcr.io/nvidia/tensorrt:<xx.xx>-py<x>
Docker 19.02 또는 그 이전 버전을 사용하면
nvidia-docker run -it --name tensorrt nvcr.io/nvidia/tensorrt:<xx.xx>-py<x>
을 사용하면 된다.
3. Pytorch TensorRT설치
Torch-TensorRT를 사용하려면 3가지 방법이 있다.
- torch_tensorrt docker image 사용
- torch_tensorrt 패키지 사용
- nvidia iot torch2trt 사용
필자는 1번 방법에서는 pytorch버전 오류, 3번에서는 성능최적화가 잘 안돼 2번을 선택했다. torch_tensorrt는 현재 v1.1.0로 pytorch v1.11.0밖에 지원이 안 된다. v1.11.0으로 설치하자 CUDA 11.3
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113
CUDA 10.2
pip install torch==1.11.0+cu102 torchvision==0.12.0+cu102 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu102
이후 torch-tensorrt를 설치하자
pip install torch-tensorrt -f https://github.com/pytorch/TensorRT/releases
4. TensorRT적용
현재 pytorch는 torch script -> onnx -> tensorrt이렇게 변환한다. 먼제 model을 선언해주자.
성능비교를 해보자
Result
| Inference Time (ms) | Model Parameter (MB) | |
| MobileNetV2 | 6.1163 | 14.2630 |
| TensorRT | 0.3954 | 0.0005 |
이렇듯 TensorRT를 이용하면 inference time이나 parameter size에서 이득을 볼 수 있다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: