[네트워크 경량화] EfficientNet
이번에 소개해드릴 논문은 EffientNet입니다. EffientNet은 ICML 2019에 나왔고, 저자는 이전에 MnasNet을 발표한 적이 있습니다.
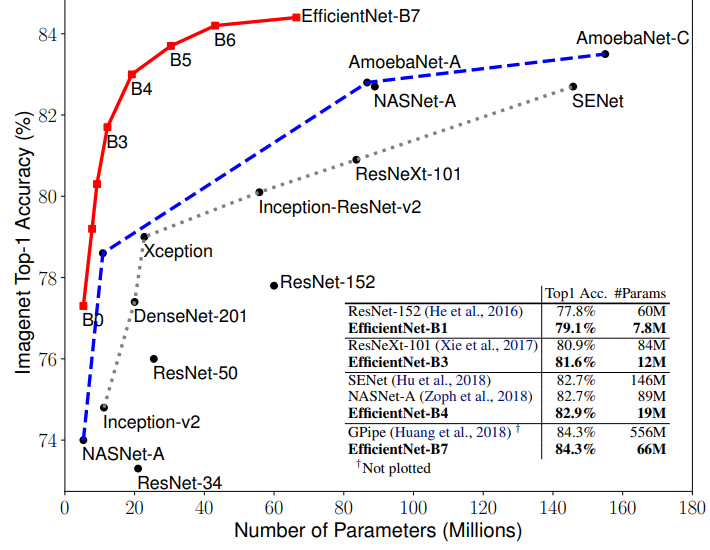
실험 결과
Introduction
ImageNet Dataset이 나온 이후에 여러 classification모델이 제안되었습니다. VGG이후 ResNet부터 네트워크를 깊게 쌓음으로써 정확도를 올리게 되었고, GPipe경우에는 base model보다 4배를 크게 만듬으로써 ImageNet에서 우승했습니다.
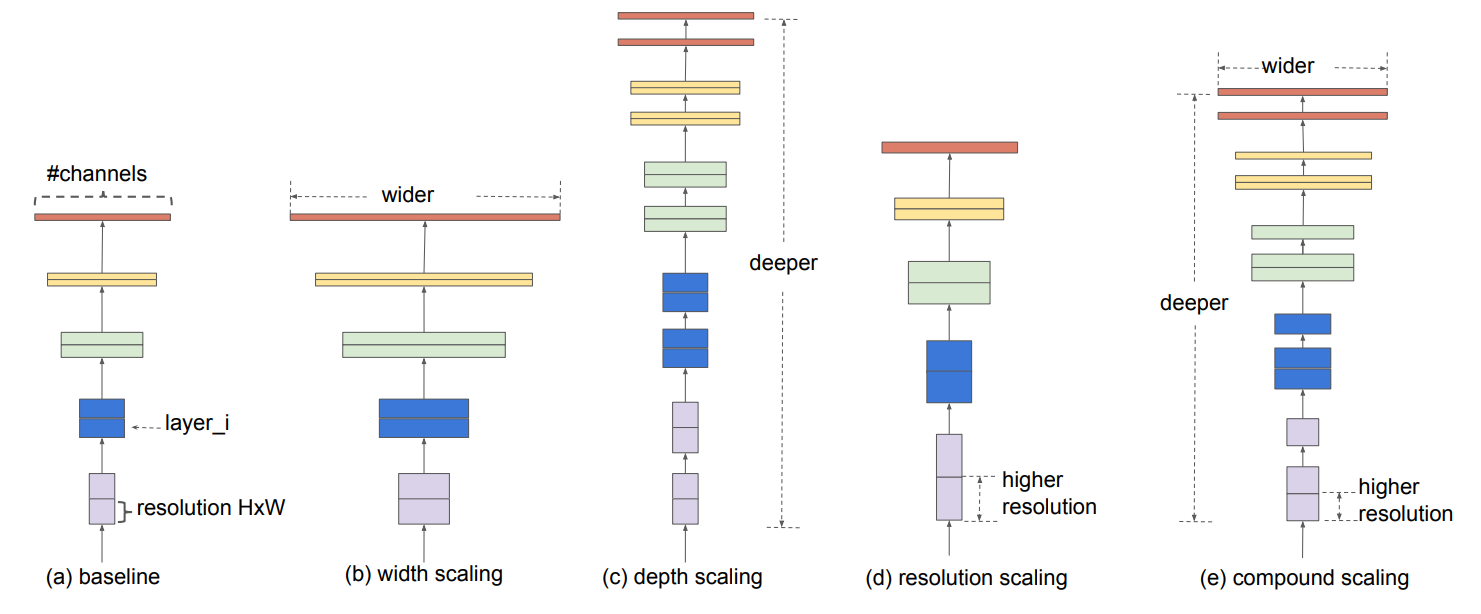
이와 같이 보통은 depth를 늘리면서 정확도를 올리고 width를 늘리거나 resolution을 늘리면서 정확도를 올리게 됩니다.
이러한 연구들을 보다 보면 depth, width, resolution이렇게 3가지를 균형을 맞추면 더 성능이 좋아지지 않을까?” 이런 생각을 갖게될 것입니다. 직관적으로 생각하면 큰 resolution의 이미지를 넣으면 receptive field가 커지게되고 그 패턴을 캡쳐하기 위해 channel수도 늘어야될 것입니다. EffientNet은 이러한 아이디어를 갖고 compound scaling method를 제안하며 기존의 네트워크의 성능을 올리게 되었고, 새로운 state-of-art모델을 제안했습니다.
Compund Model Scaling
Comvolution Filter는 다음과 같이 정의할 수 있습니다.
\(Y_i\)는 output tensor, \(X_i\)는 input tensor, \(\mathcal{F}\)는 operator입니다.
이것을 \(L_i\)개의 Layer를 쌓는다고 하면 다음과 같이 표시할 수 있습니다.
\(\mathcal{F}^{L_i}\)는 \(\mathcal{F}^{i}\)가 \(L_i\)번 반복되는 notation입니다.
이렇게 간단한 식으로 표시했지만 \(H_i, W_i, C_i\)를 각각 조절해야하기 때문에 Design Space가 너무 넓어서, design space를 좁히기 위해 다음과 같이 constant ratio를 사용하여 표현했고 다음의 수식을 optimization을 하는 것이 목표로 잡을 것 입니다.
여기서 \(\hat{F} \hat{H}, \hat{W}, \hat{C}\)는 각각 Base model의 parameter를 나타낸 것입니다.
Scaling Dimensions
자 이제 문제는 depth, width, resolution의 조합이 아닌, linear equation의 variacnce인 d, w, r를 조절하는 문제입니다. 먼저 각각의 요소의 영향을 살펴보면 다음과 같이 볼 수 있습니다.
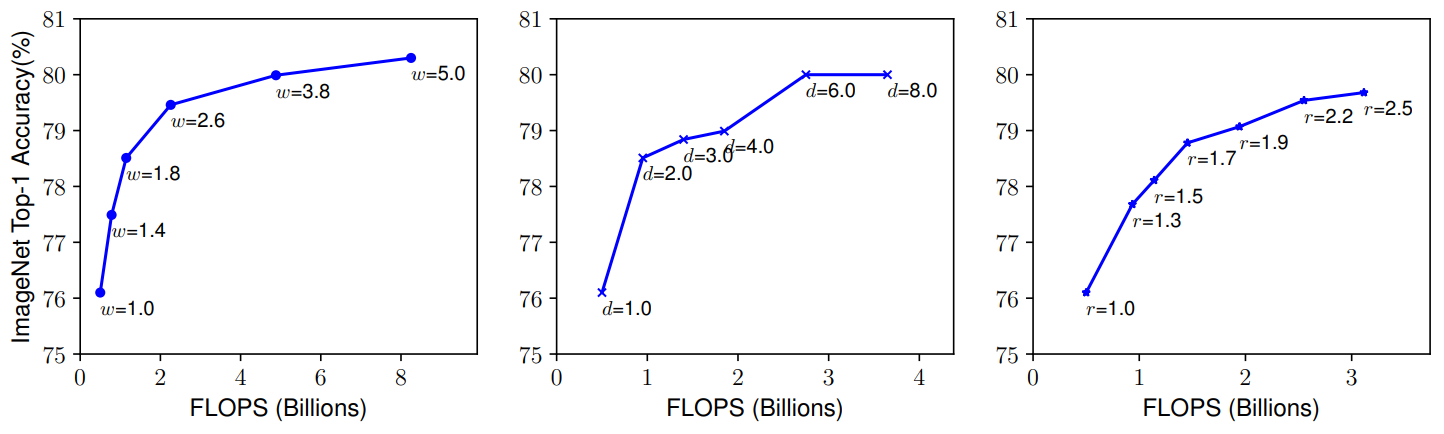
Depth(d)
직관적으로 더 깊은 ConvNet은 더 풍부하고 복잡한 feature를 찾을 수 있지만, 더 깊은 ConvNet은 vanishing gradient problem 등과 같은 문제 때문에 학습하기 힘듭니다.
Width(w)
더 큰 width를 갖는 네트워크는 또한 더 풍부하고 복잡한 feature를 찾을 수 있지만, width가 크지만 네트워크가 깊지가 않으면 high level feature를 잡을 수 없습니다.
Resolution(r)
화질이 좋은 이미지는 더욱 세세한 패턴을 잡을 수 있지만, 이미지 사이즈가 커지면 커질수록 정확도가 증가되는 양은 적어집니다.
Observation 1 - Depth, Width, Resolution를 키우면서 정확도를 높일 수 있지만, 커짐에 따라 정확도 증가율은 낮아집니다.
Compund Scaling
직관적으로 이미지의 화질이 커지면 네트워크의 깊이가 깊어져야하고 이에 따라 receptive field가 커져야 할 것입니다. 이러한 생각으로 세 가지 요소를 균형을 잡아가면서 늘려가는 것이 좋을 것입니다.
아래의 그림과 같이 depth와 resolution을 고정시키고 width만 늘리면 정확도 증가율이 낮아집니다.

Observation 2 - Observation 1의 한계를 극복하기 위해선 더 좋은 정확도를 위해서는 depth, width, resolution의 균형을 잡으면서 ConvNet의 크기를 키워야합니다.
따라서 EffientNet에서는 새로운 Compund Model Scaling을 제안했습니다.
보통 ConvNet은 \(d, w^2, r^2\)에 비례합니다. 따라서 이 논문에서는 \(\alpha \cdot \beta^2 \cdot \gamma^2 \approx 2\)을 잡고 \(\phi\)를 조절해가며 model의 capacity를 높입니다.
EffientNet
앞에서와 같은 아이디어 제안이 있지만 그래도 좋은 모델을 만드는 것이 좋기 때문에 여기서도 새로운 모델을 제안했습니다. \(ACC(m)\times[FLOPS(M)/T]^w\)을 optimization goal로 놓고 Neural Architecture Search를 해 EffientNet-B0모델을 만들었습니다. Main block은 은 squeeze-and-excitation을 추가한 mobile inverted bottleneck입니다.
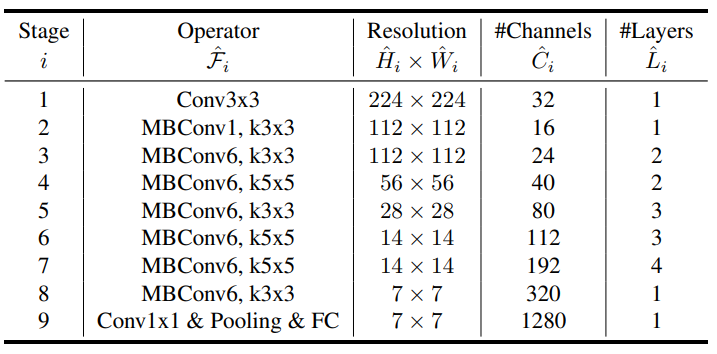
EffientNet-B0의 구조
그리고 다음 두 가지 Step으로 다른 모델을 만든다.
- \(\phi=1\)을 고정시키고 Grid Search로 찾은 값은 EffientNet-B0의 최적의 값은 \(\alpha=1.2, \beta=1.1 \gamma=1.15\)입니다.
- 다음은 \(\phi\)를 키워가면서 EffientNet-B1부터 B7를 만들었습니다.
Result
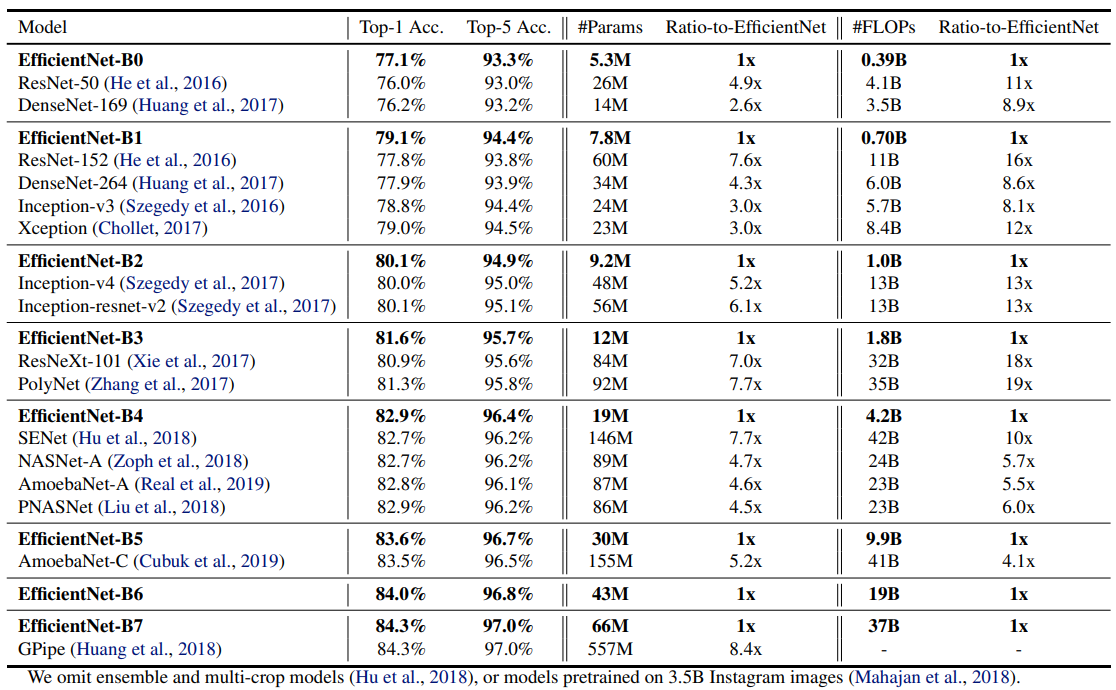
이 표에서 볼 수 있는 것과 같이 같은 Accuracy대비 FLOPS를 많이 줄일 수 있습니다.
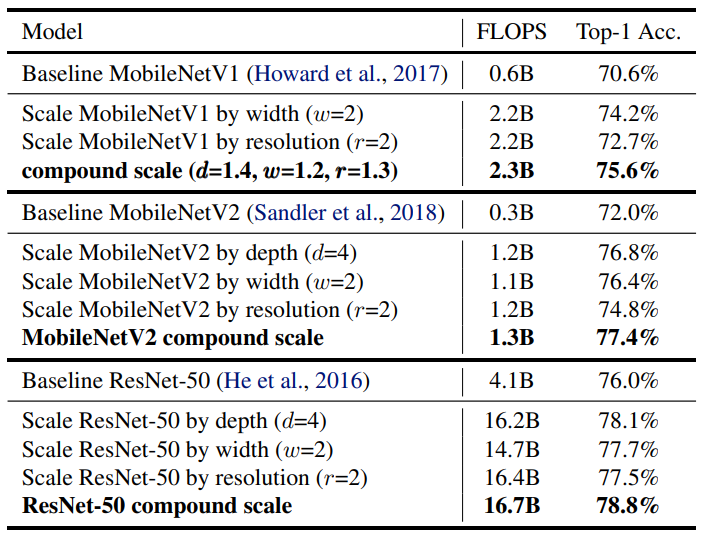
기존에 있는 네트워크에 compund scaling을 사용하면 정확도가 높아집니다.
마치며
EffientNet은 기존의 새로운 네트워크의 구조를 제안한 것이 아닌 기존의 네트워크에서 부족한 것이 무엇이 있을까라는 의문을 갖고 연구를 했습니다. depth, width, resolution는 각각 독립적인 것이 아닌 의존적이다는 것을 의식하며 연구해 좋은 성과를 냈다는 것이 좋은 연구방법과 결과라고 생각합니다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: